Minkowski’s classic theorem of “geometry of numbers” states that any convex subset of Rn which is symmetric (with respect to the origin) and of volume (with respect to Lebesgue measure) larger than 2n contains a non-zero integral point.
This theorem is used, in particular, in the classical treatment of Dirichlet’s Unit Theorem in algebraic number theory. While teaching this topic last year, I wondered whether there was an hyperbolic analogue, in the following sense, where H is the hyperbolic plane in the Poincaré model:
does there exist a constant C such that any geodesically convex subset B of the hyperbolic plane H with hyperbolic area at least C which is geodesically symmetric with respect to the point i contains at least one point z of the form g.i, where g is an element of SL(2,Z) and g.i refers to the usual action by fractional linear transformations, with z not equal to i.
Here, the subset B is geodesically convex if it contains the geodesic segment between any two points, and symmetric if, whenever x is in B, the point on the geodesic from i to x which is at distance d(i,x) from i, but in the opposite direction, is also in B.
It turns out that the answer is “No”. Indeed, C. Bavard gave the following example:
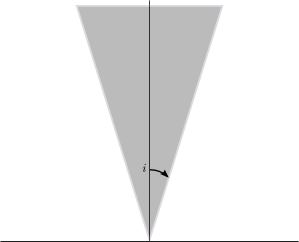
let B be a euclidean half-cone with base vertex at 0, axis the vertical axis, and angle at the origin small enough, then B does not contain any “integral” point except i, but has infinite hyperbolic area. Moreover, it is easily seen that B is convex and symmetric in the hyperbolic sense, since hyperbolic geodesics are vertical half-lines and half-circles meeting the real line at right angles.
To check the claim, it is enough to show that for any integral point z=g.i distinct from i, the ratio |x|/y has a positive lower bound, where z=x+iy (this will show that the angle from the vertical axis is bounded from below, so the point is not in a cone like the one above with sufficiently small angle). But z is given by (ai+b)/(ci+d) with a, b, c, d integers and ad-bc=1, and this ratio is simply |ac+bd|. Being an integer, either it is 0, or it is at least 1. Manipulating things, one checks that the first case only occurs for matrices in SL(2,Z) which are orthogonal matrices, and those fix i, so the point is then z=i. Hence, except for this case, the ratio is at least 1 and this concludes the argument.
It is interesting to see what breaks down in the (very simple) proofs of Minkowski’s theorem in the plane. In the first proof found on page 33 of the 5th edition of Hardy and Wright’s “An introduction to the theory of numbers” (visible here), the problem is that there is no way to dilate the convex region B in a homogeneous way compatible with the SL(2,Z) action. In other words, SL(2,Z) is essentially a maximal discrete subgroup of SL(2,R) (maybe it is maximal? I can’t find a reference).








